Smart insurance for smart drivers




Insurance for self-employed drivers and riders
Motor insurance doesn’t have to be complicated. We use smart technology to keep things simple, leaving you to focus on your work. It’s what we call clever cover.
Private hire taxi insurance

Get all-in-one cover for taxi work and personal driving, with policies running from 1 month to a whole year. Plus, use the Zego Sense app to drive safely and earn discounts when you renew.
- Flexible cover for private hire work (and deliveries)
- Choose monthly or annual insurance to suit you
- Public liability cover included as standard
- Drive well and pay less with the Sense app
Learn more about private hire insurance
Get a quote
Car & scooter delivery insurance
Whether you’re carrying parcels for Amazon or food for Just Eat, our flexible delivery insurance gives you all the right cover when you need it. All in one app.


Car delivery insurance
- Flexible insurance for deliveries and courier work
- Make changes and manage your policy in the app
- Work with all the big platforms and providers
- Public liability cover included as standard
Learn more about car delivery insurance


Scooter & motorbike delivery insurance
- Choose insurance by the hour, month or year
- Get cover for delivery work and personal riding
- Manage your cover on-the-go with our app
- Work with all the big platforms and providers
Learn more about scooter & motorbike delivery insurance
Business and courier van insurance
Your work van is more than just a set of wheels. It’s a key part of your business. Whether you’re a delivery driver or a busy tradesperson, we’ve got the right cover for you and your van.

Business van insurance
- Comprehensive van insurance for all types of work
- Includes personal belongings and tools in transit (limits apply)
- Boost your cover with a range of optional extras
- Drive well and save money at renewal with the Sense app
Learn more about business van insurance

Courier van insurance
- Combined cover for delivery work and personal driving
- Includes public liability insurance as standard
- Get all the cover you need to stay safe while you work
- Manage your policy easily in the app
Learn more about courier van insurance
Insurance for the way you work
As a self-employed driver or rider, you need insurance that fits around you. Cover that saves you time and money. Because if your driving gig is flexible, your insurance should be, too.

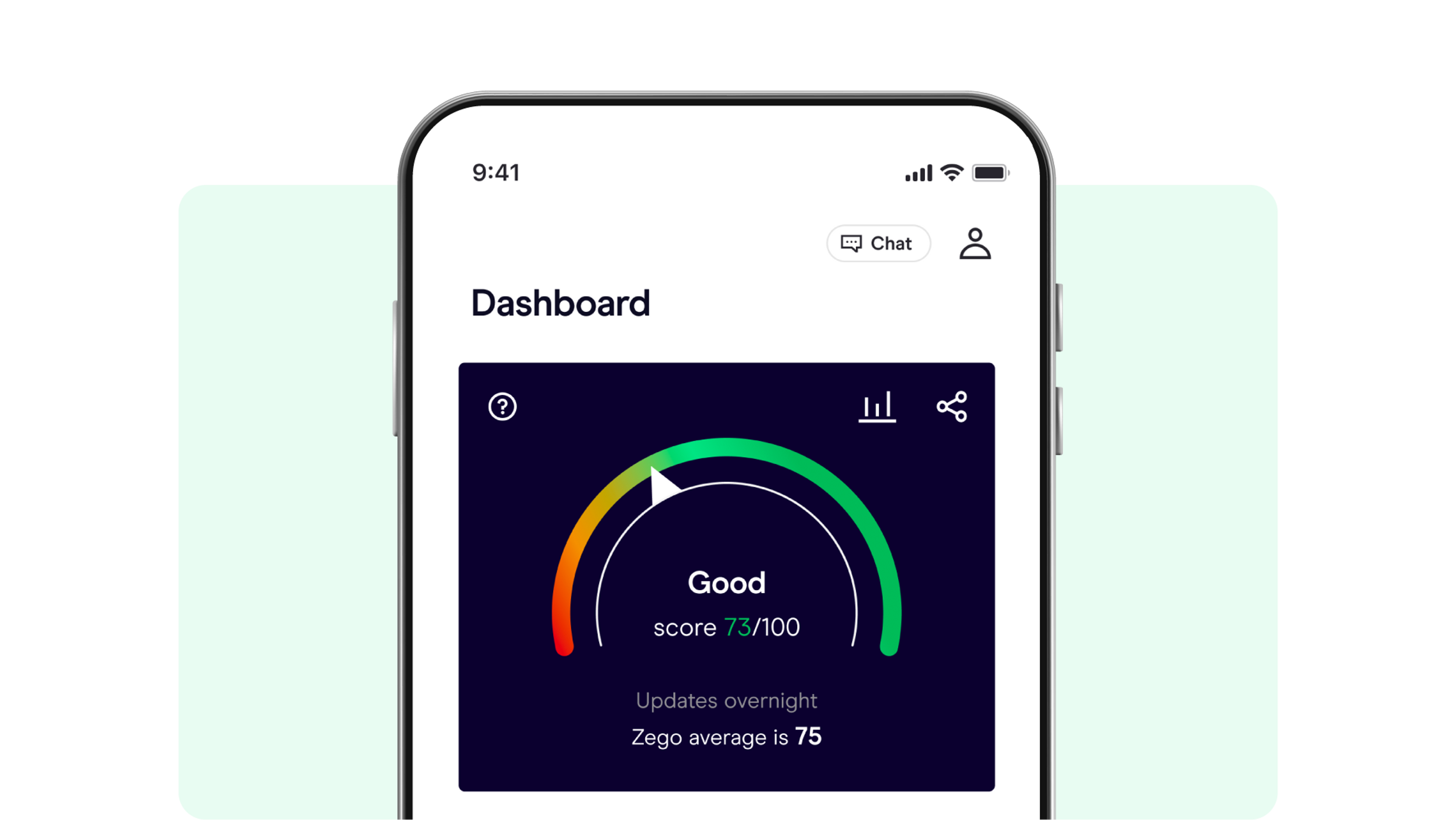
Zego Sense
Insurance for good drivers
Drive safely and earn discounts on your private hire or business van insurance when you choose a Sense policy. The better you drive, the less you pay.
- The app measures how you drive to give you a score.
- A higher score means a lower cost when you renew.
- Save money upfront, just for choosing Sense.
- Then drive well to save even more at renewal.
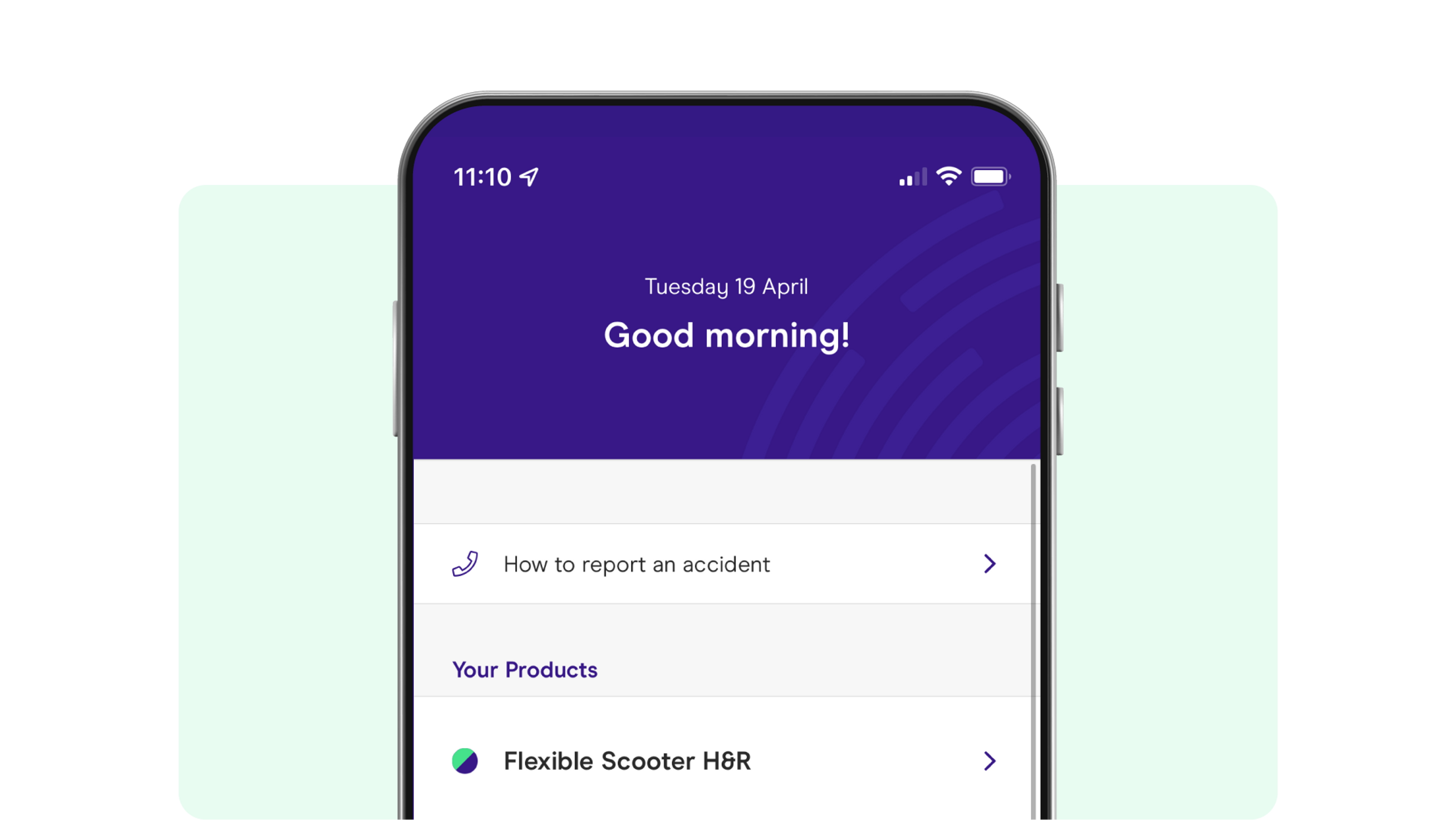
Zego Delivery
App-based cover for busy delivery drivers
Keep your policy in your pocket with the Delivery app. Insurance that flexes around you.
- Delivery insurance by the hour, month or year.
- Access all your policy documents in the app.
- Renew your cover and make changes when you need to.
- Top up your account and link with any work provider.
Our partners













Our partners
Clever cover for your fleet

Safer trips. Healthier fleets. Greater rewards.
Take control of your fleet insurance with powerful tools, simple policy management and smart insights to make your fleet safer.
Learn about Zego


Our story
It started with us powering opportunities for self-employed drivers and riders. Now we're working with businesses right across the UK and Europe.


Work with us
We thrive on curiosity, on thinking differently, and through diverse experiences. People who push for progress day-in, day-out. People like you!

The Zego Blog
Find more information on how to get the most out of your insurance, whether your’re a self-employed driver or managing an entire fleet.
Invite your friends, earn rewards

Get up to £50 for you and them
We think sharing is caring. That’s why we’ll give you and a friend £50 when they take out an annual policy with us, or £10 for a 30-day policy. Simply share the referral link from your account. The more you refer, the more you earn!